Meet Gemma 3n: Google's Lightweight, Open Language Model


In the ever-evolving landscape of open language models, Google just dropped something exciting: Gemma 3n — the latest and smallest sibling in the Gemma family, optimized for local, efficient deployment and fine-tuning.
But don’t let its size fool you.
🔍 What is Gemma 3n?
Gemma 3n is part of Google DeepMind's initiative to make state-of-the-art language models more accessible and privacy-friendly. Unlike the larger Gemma 2B and 7B models, 3n (where "n" stands for "nano") is designed to run directly on-device — think laptops, mobile phones, or edge hardware — without relying on the cloud.
This makes it a compelling option for:
Privacy-preserving AI apps
Educational tools
Local chatbots and agents
Lightweight research experiments
Embedded AI systems
⚙️ Key Specs
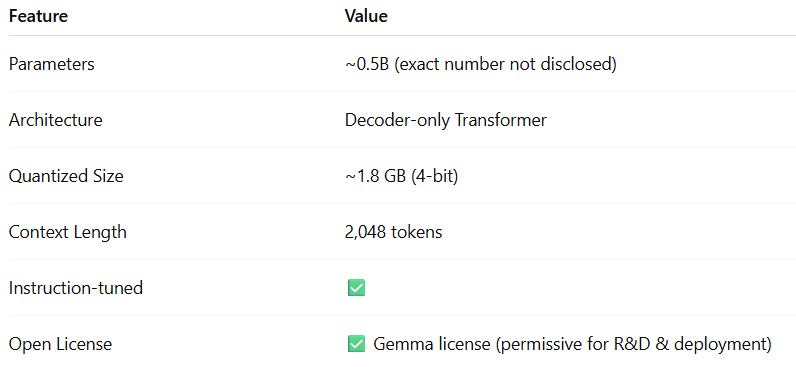
Despite its compact size, Gemma 3n supports instruction following and general-purpose generation tasks surprisingly well. It's trained using the same high-quality data curation and filtering pipeline used for its bigger counterparts.
🚀 Why It Matters
We’re entering a new era where on-device AI it’s becoming standard practice. Apple is expected to release local LLM features in iOS 18, and open models like Gemma 3n help democratize access without compromising privacy or user control.
Gemma 3n also integrates seamlessly with:
KerasNLP – Streamlined integration for training and inference with familiar Keras workflows.
JAX, PyTorch, TF – Broad support across top ML frameworks for flexible experimentation and deployment.
Gemma.cpp (CPU/GPU inference) – Lightweight, fast inference on local machines — no cloud required.
LLM inference libraries like HuggingFace Transformers – Plug-and-play compatibility for rapid prototyping and fine-tuning.s
This opens doors for hobbyists, researchers, and startups to build nimble, privacy-aware applications without massive infrastructure.
🔧 Getting Started
To try it out:
Visit the Gemma 3n documentation
Download the model from Hugging Face or Kaggle
Choose your preferred runtime: Python, C++, or even browser-based via WebLLM
Run it locally using
gemma.cppor a Hugging Face pipeline
Fine-tuning, quantization, and deployment examples are already available in the official Colab notebooks.
🧩 Final Thoughts
Gemma 3n might not beat GPT-4 in a benchmark brawl, but that’s not the point. It’s about fast, flexible, and local AI — which opens new frontiers for embedded systems, privacy-first apps, and accessibility.
With its tiny footprint and impressive adaptability, Gemma 3n is worth watching — and building on.
✉️ What will you build with it? Let me know in the comments or reply to this post!